
From Pipelines to Platforms: Modern Engineering for Regulated Data Teams

Image created by the author
If you work in a regulated data environment: pharma, med devices, clinical research, chances are you’ve heard a version of this sentence:
“That’s just how it’s always been done.”
In practice, that often means:
- Data ingestion, transformation, and delivery handled separately by different teams, using different tools, with no central data warehouse or shared infrastructure.
- Manual handoffs between roles that slow delivery and increase risk.
- Compliance checks treated as a separate, end-of-process task instead of being built into the workflow.
Automation has helped in some areas, but the underlying patterns haven’t changed. Teams are still solving the same problems repeatedly, often in isolation and with little code reuse or standardization. When code is reused, it’s often copied manually from one study to the next.
The challenge isn’t just outdated tools — it’s the lack of shared systems, orchestration, and standardized processes that can make data ingestion to delivery scalable and repeatable across studies and therapeutic areas.
That’s where data engineering meets platform engineering.
What Is Data Engineering?

Image created by the author
In most industries, data engineering focuses on building orchestrated pipelines that manage the full data lifecycle: Extract, Transform, Load (ETL). These pipelines ingest data from source systems, transform it into the required structure, and deliver it to consumers, such as analysts, study teams, or downstream applications.
Well-designed pipelines are reusable, testable, and maintainable, rather than manual, study-specific processes.
In regulated pharma, SDTM and ADaM work is typically limited to the Transform step. Statistical programmers write manual, study-specific code with little reuse, while Extract and Load are handled separately through ad-hoc sFTP transfers or one-off scripts, leaving delivery as a manual handoff.
In a true data engineering model, ingestion, transformation, and delivery are connected through orchestration. For example, an organization might maintain centralized RAW and PROD data layers, with transformation jobs producing SDTM and ADaM outputs as part of the same pipeline.
In most pharma organizations today, this kind of end-to-end pipeline still doesn’t exist. While some teams are adapting, the shift is long overdue.
💡 Example Imagine your organization uses Snowflake as its central data warehouse.
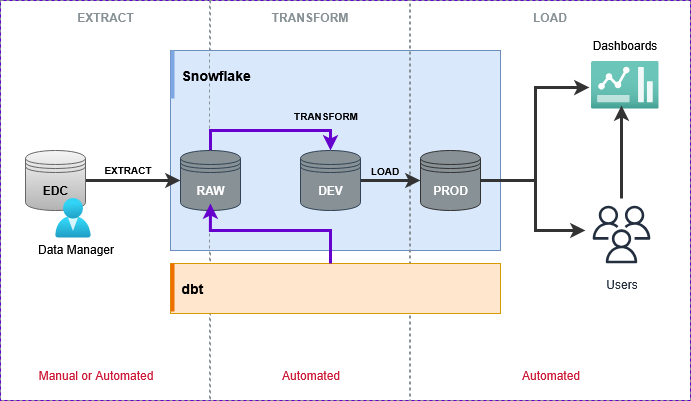
Example ETL pipeline using Snowflake and dbt (data build tool)
1. EXTRACT: A data manager exports cleaned EDC data and loads it into the RAW schema in Snowflake - This can be manual or batch automated.
2. TRANSFORM: That load event automatically triggers a dbt (data build tool) pipeline that applies SDTM and ADaM transformations.
3. LOAD: Once the transformations pass automated compliance checks, the outputs are written to a PROD schema in Snowflake.
From there, authorized teams can connect directly to the PROD datasets:
- Statisticians run analyses without waiting for manual dataset deliveries.
- Medical monitors can view custom dashboards showing patient progress, safety metrics, and study KPIs.
- Other stakeholders can access the same trusted, validated data for their own tools and reporting needs.
In this model:
- Data engineering builds the automated flow from RAW → dbt → PROD, plus the connections to analytics tools + dashboards.
What Is Platform Engineering?

Image created by the author
“In a platform engineering approach, one or more teams—often referred to as the platform engineering team or the platform team—build a comprehensive set of shared tools and services (aka “the platform”) to help development teams develop, deploy, and operate cloud infrastructure on a self-service basis. This includes cloud infrastructure, container orchestration platforms, databases, networking, monitoring, code repositories, and deployment pipelines.” — Pulumi
At this point, you might be thinking: “Cloud infrastructure won’t work here.”
That concern is common in regulated industries, and it’s exactly the kind of mindset I addressed in this earlier article.
Platform engineering for data teams is about building the foundations that let data work scale safely and consistently.
Rather than every team adapting tools differently for each study, the platform team provides standardized, self-service building blocks:
- Infrastructure as Code (IaC) to provision environments (e.g., RAW, DEV, PROD schemas in Snowflake).
- Guardrails like access controls, logging, monitoring, and compliance baked in from the start.
- Reusable workflows that handle repetitive steps (e.g., data ingestion, testing, transformation pipelines).
💡 Note: A “platform” in this case, isn’t a product you buy — it’s a deliberate way of working.
For example, when starting a new study, a statistical programmer might self-service request a Snowflake environment setup (RAW/DEV/PROD), allowing the data manager to begin loading data from the EDC into RAW.
Instead of opening tickets, the programmer triggers an automated workflow (via portal, CLI, or API) that provisions the schemas with access controls and compliance built in.
All of this is deployed through the IaC templates managed by the platform team. This ensures consistency and speed without extra manual setup.
How This Changes the Statistical Programmer’s Role
Traditionally, statistical programmers wrote study-specific SAS programs to transform raw EDC data into SDTM, rebuilding much of the process from scratch for every study.
With a platform-enabled pipeline, SDTM creation is no longer a one-off coding exercise. The domain-specific transformation logic now lives in maintainable, version-controlled models (e.g., dbt models) that can be refined and reused across studies.
The shift looks like this:
- Before: Procedural, study-specific SAS code used to generate SDTM datasets.
- Now: Standardized transformation models that automatically produce SDTM datasets as new data arrives, freeing time for higher-value work such as TFLs (Tables, Figures, Listings) and custom or ad-hoc outputs for study teams and biostatistics.
SAS remains important for regulatory and sponsor deliverables, but effort shifts away from re-coding transformations toward TFLs, exploratory analyses and special requests.
💡 Think of it like this:
- Data engineering defines what to move and transform.
- Platform engineering defines how it gets done by providing the operating model and blueprints.
- Analytics engineering (the direction programmers move in with this model) ensures the transformation layer is reliable, so programmers can devote more time to analysis-ready deliverables like TFLs and custom outputs.
How Data Engineering and Platform Engineering Intersect
Data engineering and platform engineering are complementary disciplines.
- Data engineering focuses on building the pipelines that deliver data so it’s ready for use.
- Platform engineering focuses on creating the shared systems, automation, and infrastructure that make those pipelines scalable, compliant, and reusable across projects.
When combined, the result is an orchestrated, self-service data platform where ingestion, transformation, and delivery are connected into a single, automated process.
Instead of manually rebuilding the same logic for each study, teams can focus on solving new problems.
If you’re still unclear on these concepts, refer to my explainer:
👉 What Is Data Platform Engineering?
Why This Matters In Regulated Industries
Regulated data teams are a perfect candidate for platform thinking because:
- Patterns repeat — SDTM, ADaM, CDASH are mostly stable.
- Compliance is non-negotiable, so it can be integrated.
- Audit trails are a requirement.
- Multiple teams touch the same workflows across studies and indications.
A platform approach can:
- Reduce duplicate work across studies
- Ensure compliance checks run automatically
- Let statisticians, programmers, and data managers work without waiting for engineering support every time
- Make it easier to adapt to new standards or tech without starting from scratch
Why Now?
Platform engineering is still evolving, and in regulated data teams it remains largely uncharted. That’s why the timing matters. Designing systems for yesterday’s workflows leaves teams unprepared for what’s next, from real-time submissions to AI-assisted compliance and higher-value work.
Closing Thought
While platform engineering varies by industry, platform thinking shifts the focus from delivering a single project to building the capability to deliver projects well.
If you’ve ever thought, “There has to be a better way,” you’re probably right. The first step may be to think like a platform engineer.
Next in the Series
In this article, we explored the broader concept of Data & Platform Engineering and why regulated teams need more than just new tools.
Modernization happens across two connected layers:
- Data Engineering
- Platform Engineering
In the next article, I’ll take a closer look at the Data Engineering layer and show what a modernized pipeline can look like in practice:
📄➡️ From Fragmented Data Flows to a Governed Data Pipeline
💬 If you’re enjoying the ideas here and want to stay connected, feel free to connect with me on LinkedIn. I’d love to stay in touch with others thinking about the future of clinical data and systems design.
Disclaimer: This article reflects my personal views only and is for informational purposes. It does not represent professional advice or the positions of any past or current employer. No confidential or proprietary information is shared, and I disclaim all liability for how you use its content. Third-party links or tool mentions are not endorsements.