Clinical Data Modernization Is an Architecture Problem Before It Is an AI Problem
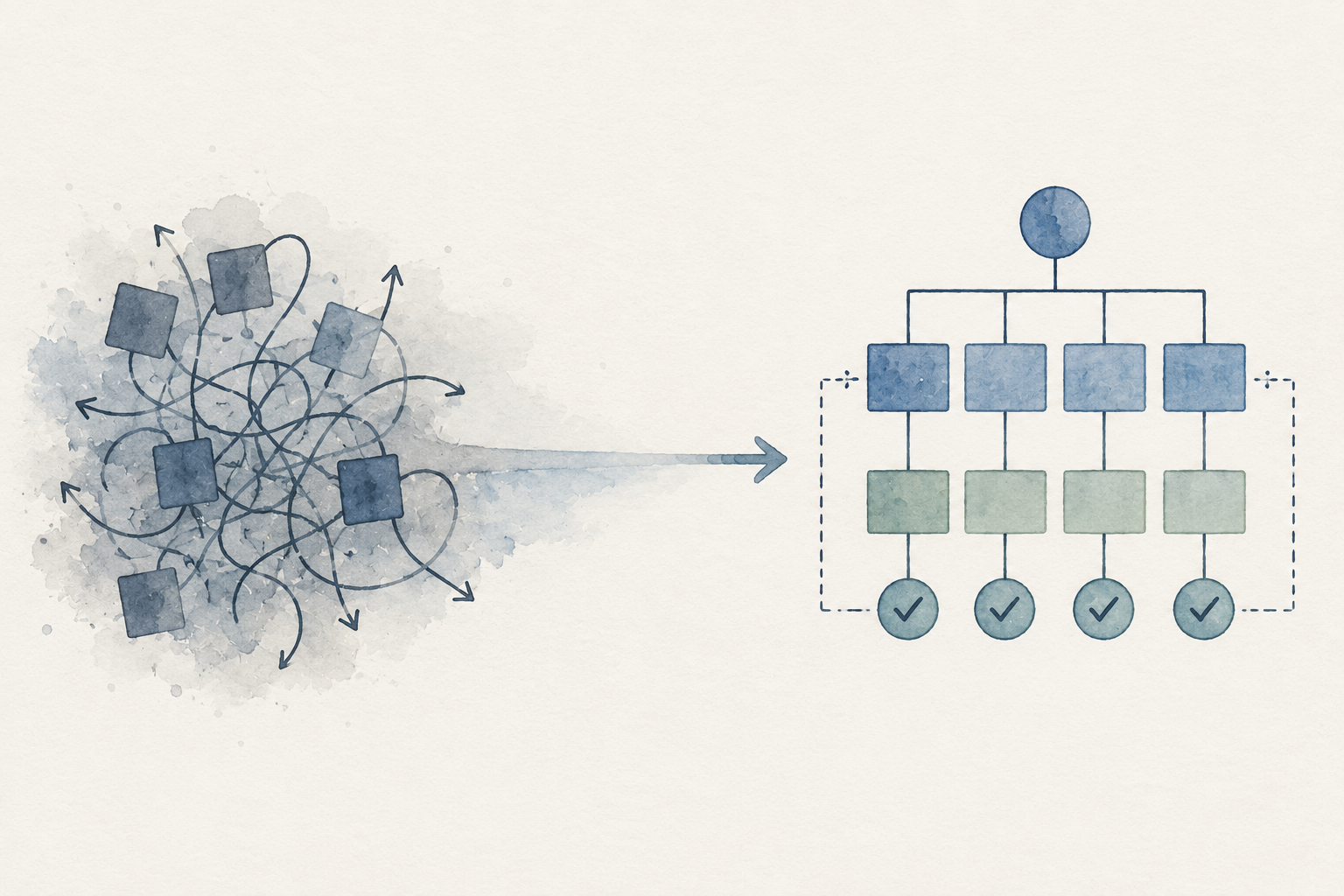
Image created by the author
“Move fast and break things” was a common philosophy during earlier eras of software development. Over time, many engineering organizations moved away from that mindset because repeatedly rebuilding large systems quickly without strong architectural foundations created significant maintenance burden, operational overhead, and technical debt.
In many ways, parts of clinical data workflows still resemble earlier software engineering eras.
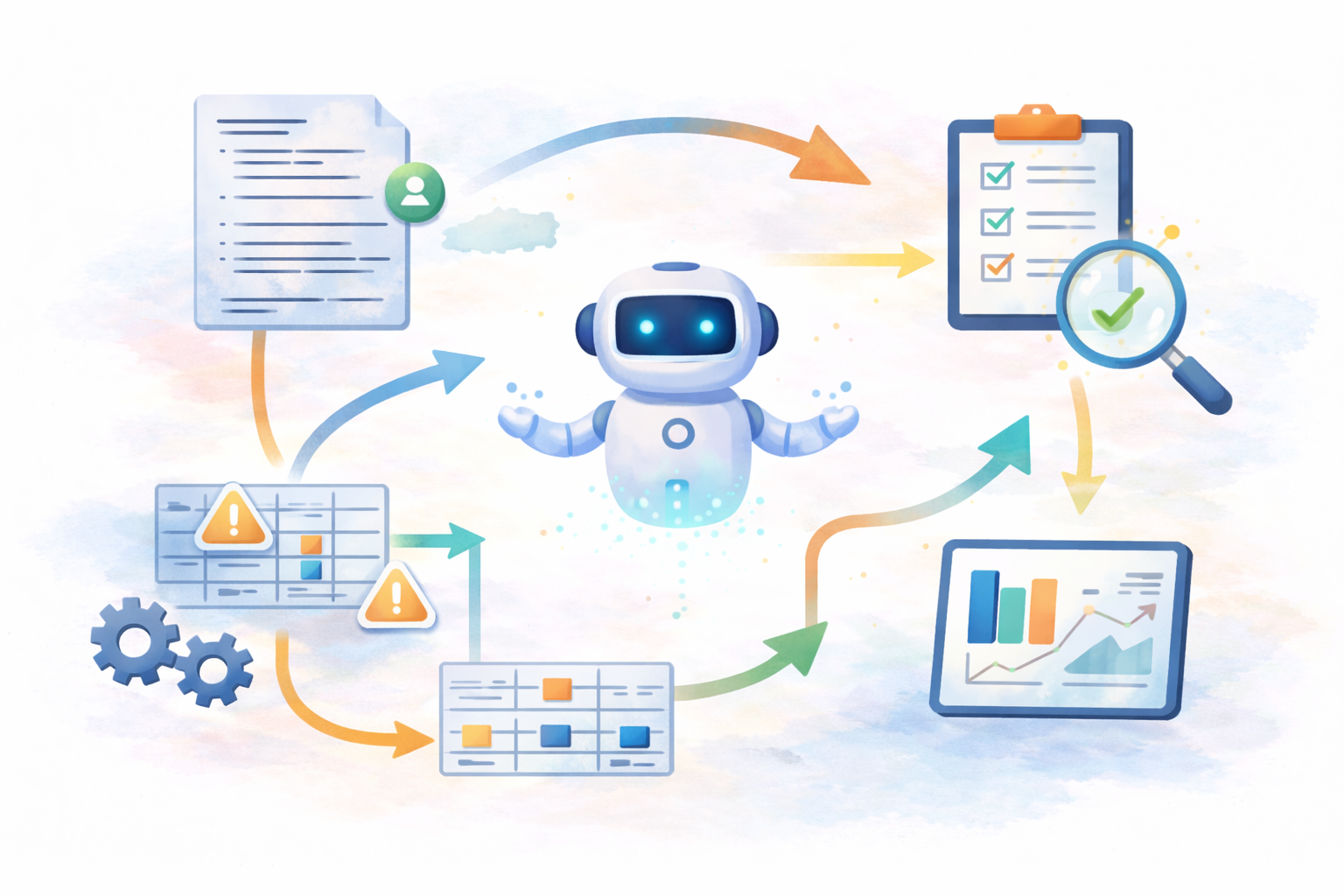
Clinical programming workflows often remain highly repetitive, heavily manual, and rebuilt repeatedly in slightly different ways across studies. Even when studies share similar structural concepts, large portions of the implementation are frequently recreated from scratch. Over time, this creates operational inconsistency, validation burden, and technical debt that becomes increasingly difficult to scale.
This becomes especially important in regulated environments where traceability, repeatability, and reviewability are critical.
For that reason, I do not think the primary bottleneck in clinical data modernization is currently a lack of AI capability.
Adding additional layers of automation or AI on top of inefficient workflow architecture risks increasing long-term technical debt.
To me, the larger challenge is operational design.
This thought process has heavily influenced the direction of my SDTM Blueprint-as-a-Service project. The project explores how metadata-driven architecture and reusable workflow structures can reduce repetitive structural work while preserving the study-specific logic and interpretation required for clinical programming.
In this architecture, derivations and transformation logic are contributed into standardized workflow structures instead of repeatedly rebuilding large study-specific programs from scratch for every study.
Conceptually, the architecture separates:
- Structural workflow generation
- Metadata interpretation and normalization
- Derivation injection points
- Workflow validation checkpoints
- Study-specific transformation logic
The goal is to reduce the amount of repetitive infrastructure work surrounding the programming itself.
At a high level, I imagine the workflow evolving toward a reusable platform-style operational model where metadata ingestion, scaffolding generation, validation, and execution pipelines become standardized workflow layers, while programmers focus primarily on study-specific derivations, business logic, and clinical edge cases.
flowchart TD
A[Programmer Assigned Study] --> B[Initialize Study Workspace]
B --> C[Generate Folder Structure]
C --> D[Generate Base Config Files]
D --> E[Pull CDISC API Metadata]
E --> F[ODM-XML / ODM-JSON Extraction]
F --> G[Metadata Matching + Normalization]
G --> H[Generate SDTM Scaffolding]
H --> I[Programmer Reviews Scaffold + Specs]
subgraph Programmer["Programmer Layer"]
I --> J[Create Standard Derivation Injections]
I --> K[Create Custom Derivation Injections]
I --> L[Adjust Configurations / Rules]
end
J --> M[Execute dbt Workflow]
K --> M
L --> M
M --> N[Validation + CI/CD Checks]
N --> O[Standardized SDTM Outputs]
O --> P[Review / Iteration]
In this model, programmers remain responsible for study-specific derivations, business logic, and clinical edge cases. The difference is that much of the repetitive structural setup work surrounding those activities becomes standardized through reusable workflow layers, metadata-driven scaffolding, validation checkpoints, and execution pipelines.
In many software domains, abstraction layers evolved because repeatedly rebuilding the same structural patterns became operationally inefficient. Frameworks, reusable modules, infrastructure-as-code, CI/CD pipelines, and platform engineering practices emerged to standardize workflow structure while allowing teams to focus on the logic unique to their problem space.
I believe clinical data workflows are beginning to face many of the same pressures.
AI may eventually assist many parts of clinical programming in meaningful ways. However, sustainable automation becomes significantly more realistic when the surrounding workflow is structured, standardized, and easier to validate.
For me, that is currently the more interesting engineering problem.
Disclaimer: This article reflects my personal views only and is for informational purposes. It does not represent professional advice or the positions of any past or current employer. No confidential or proprietary information is shared, and I disclaim all liability for how you use its content. Third-party links or tool mentions are not endorsements.